So far we have mostly discussed LiquidHaskell in the context of
recursive data structures like lists, but there comes a time in
many programs when you have to put down the list and pick up an
array for the sake of performance.
In this series we’re going to examine the text library, which
does exactly this in addition to having extensive Unicode support.
text is a popular library for efficient text processing.
It provides the high-level API Haskellers have come to expect while
using stream fusion and byte arrays under the hood to guarantee high
performance.
Suppose we wanted to get the ith Char of a Text,
we could write a function1
42: charAt (Text a o l) i = word2char $ unsafeIndex a i 43: where word2char = chr . fromIntegral
which extracts the underlying array, indexes into it, and casts the Word16
to a Char, using functions exported by text.
Let’s try this out in GHCi.
51: ghci> let t = T.pack "dog" 52: ghci> charAt t 0 53: 'd' 54: ghci> charAt t 2 55: 'g'
Looks good so far, what happens if we keep going?
59: ghci> charAt t 3 60: '\NUL' 61: ghci> charAt t 100 62: '\8745'
Oh dear, not only did we not get any sort of exception from Haskell, we weren’t even stopped by the OS with a segfault. This is quite dangerous since we have no idea what sort of data (private keys?) we just read! To be fair to Bryan O’Sullivan, we did use a function that was clearly marked unsafe, but I’d much rather have the compiler throw an error on these last two calls.
In this post we’ll see exactly how prevent invalid memory accesses like this with LiquidHaskell.
78: {-# LANGUAGE BangPatterns, CPP, MagicHash, Rank2Types, RecordWildCards, UnboxedTuples, ExistentialQuantification #-} 80: {-@ LIQUID "--no-termination" @-} 81: module TextInternal where 82: 83: import Control.Exception (assert) 84: import Control.Monad.ST.Unsafe (unsafeIOToST) 85: import Data.Bits (shiftR, xor, (.&.)) 86: import Data.Char 87: import Foreign.C.Types (CSize) 88: import GHC.Base (Int(..), ByteArray#, MutableByteArray#, newByteArray#, 89: writeWord16Array#, indexWord16Array#, unsafeCoerce#, ord, 90: iShiftL#) 91: import GHC.ST (ST(..), runST) 92: import GHC.Word (Word16(..)) 93: 94: import qualified Data.Text as T 95: import qualified Data.Text.Internal as T 96: 97: import Language.Haskell.Liquid.Prelude 98: 99: {-@ data Array = Array { aBA :: ByteArray# 100: , aLen :: Nat 101: } 102: @-} 103: 104: {-@ aLen :: a:Array -> {v:Nat | v = (aLen a)} @-} 105: 106: 107: {-@ maLen :: a:MArray s -> {v:Nat | v = (maLen a)} @-} 108: 109: new :: forall s. Int -> ST s (MArray s) 110: unsafeWrite :: MArray s -> Int -> Word16 -> ST s () 111: unsafeFreeze :: MArray s -> ST s Array 112: unsafeIndex :: Array -> Int -> Word16 113: copyM :: MArray s -- ^ Destination 114: -> Int -- ^ Destination offset 115: -> MArray s -- ^ Source 116: -> Int -- ^ Source offset 117: -> Int -- ^ Count 118: -> ST s () 119: 120: {-@ memcpyM :: MutableByteArray# s -> CSize -> MutableByteArray# s -> CSize -> CSize -> IO () @-} 121: memcpyM :: MutableByteArray# s -> CSize -> MutableByteArray# s -> CSize -> CSize -> IO () 122: forall a. (GHC.Prim.MutableByteArray# a) -> Foreign.C.Types.CSize -> (GHC.Prim.MutableByteArray# a) -> Foreign.C.Types.CSize -> Foreign.C.Types.CSize -> (GHC.Types.IO ())memcpyM = forall a. aundefined 123: 124: -------------------------------------------------------------------------------- 125: --- Helper Code 126: -------------------------------------------------------------------------------- 127: {-@ predicate RoomN N MA I = (I+N <= (maLen MA)) @-} 128: 129: {-@ writeChar :: ma:MArray s -> i:{Nat | i < (maLen ma) - 1} -> Char 130: -> ST s {v:Nat | (RoomN v ma i)} 131: @-} 132: writeChar :: MArray s -> Int -> Char -> ST s Int 133: forall a. x1:(TextInternal.MArray a) -> x2:{v : GHC.Types.Int | (v >= 0) && (v < ((maLen x1) - 1))} -> GHC.Types.Char -> (GHC.ST.ST a {v : GHC.Types.Int | (v >= 0) && ((x2 + v) <= (maLen x1))})writeChar (TextInternal.MArray a)marr {v : GHC.Types.Int | (v >= 0) && (v < ((maLen marr) - 1))}i GHC.Types.Charc 134: | {x2 : GHC.Types.Int | (x2 == n)}n x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 < x2))}< {x2 : GHC.Types.Int | (x2 == (65536 : int))}0x10000 = do 135: x1:(TextInternal.MArray a) -> {x6 : GHC.Types.Int | (x6 >= 0) && (x6 < (maLen x1))} -> GHC.Word.Word16 -> (GHC.ST.ST a ())unsafeWrite {x2 : (TextInternal.MArray a) | (x2 == marr)}marr {x4 : GHC.Types.Int | (x4 == i) && (x4 >= 0) && (x4 < ((maLen marr) - 1))}i (x1:GHC.Types.Int -> {x2 : GHC.Word.Word16 | (x2 == x1)}fromIntegral {x2 : GHC.Types.Int | (x2 == n)}n) 136: {x26 : GHC.Types.Int | ((m == 1) => (x26 == (hi * 2))) && ((m == 1) => (x26 == (i * 2))) && ((m == 1) => (x26 == (lo * 2))) && ((m == 1) => (x26 == (m * 2))) && ((m == 1) => (x26 == (n * 2))) && (x26 == 1) && (x26 > 0) && (x26 > m) && (x26 < (maLen marr)) && ((i + x26) <= (maLen marr)) && ((m + x26) <= (maLen marr))} -> (GHC.ST.ST a {x26 : GHC.Types.Int | ((m == 1) => (x26 == (hi * 2))) && ((m == 1) => (x26 == (i * 2))) && ((m == 1) => (x26 == (lo * 2))) && ((m == 1) => (x26 == (m * 2))) && ((m == 1) => (x26 == (n * 2))) && (x26 == 1) && (x26 > 0) && (x26 > m) && (x26 < (maLen marr)) && ((i + x26) <= (maLen marr)) && ((m + x26) <= (maLen marr))})return {x2 : GHC.Types.Int | (x2 == (1 : int))}1 137: | otherwise = do 138: x1:(TextInternal.MArray a) -> {x6 : GHC.Types.Int | (x6 >= 0) && (x6 < (maLen x1))} -> GHC.Word.Word16 -> (GHC.ST.ST a ())unsafeWrite {x2 : (TextInternal.MArray a) | (x2 == marr)}marr {x4 : GHC.Types.Int | (x4 == i) && (x4 >= 0) && (x4 < ((maLen marr) - 1))}i {x2 : GHC.Word.Word16 | (x2 == lo)}lo 139: x1:(TextInternal.MArray a) -> {x6 : GHC.Types.Int | (x6 >= 0) && (x6 < (maLen x1))} -> GHC.Word.Word16 -> (GHC.ST.ST a ())unsafeWrite {x2 : (TextInternal.MArray a) | (x2 == marr)}marr ({x4 : GHC.Types.Int | (x4 == i) && (x4 >= 0) && (x4 < ((maLen marr) - 1))}ix1:GHC.Types.Int -> x2:GHC.Types.Int -> {x4 : GHC.Types.Int | (x4 == (x1 + x2))}+{x2 : GHC.Types.Int | (x2 == (1 : int))}1) {x2 : GHC.Word.Word16 | (x2 == hi)}hi 140: {x32 : GHC.Types.Int | ((hi == 1) => (x32 == (hi * 2))) && ((i == 1) => (x32 == (i * 2))) && ((lo == 1) => (x32 == (lo * 2))) && ((m == 1) => (x32 == (m * 2))) && ((n == 1) => (x32 == (hi * 2))) && ((n == 1) => (x32 == (i * 2))) && ((n == 1) => (x32 == (lo * 2))) && ((n == 1) => (x32 == (m * 2))) && ((n == 1) => (x32 == (n * 2))) && (x32 > 0) && (x32 >= 0) && (x32 < n) && (x32 <= (maLen marr)) && ((i + x32) <= (maLen marr))} -> (GHC.ST.ST a {x32 : GHC.Types.Int | ((hi == 1) => (x32 == (hi * 2))) && ((i == 1) => (x32 == (i * 2))) && ((lo == 1) => (x32 == (lo * 2))) && ((m == 1) => (x32 == (m * 2))) && ((n == 1) => (x32 == (hi * 2))) && ((n == 1) => (x32 == (i * 2))) && ((n == 1) => (x32 == (lo * 2))) && ((n == 1) => (x32 == (m * 2))) && ((n == 1) => (x32 == (n * 2))) && (x32 > 0) && (x32 >= 0) && (x32 < n) && (x32 <= (maLen marr)) && ((i + x32) <= (maLen marr))})return {x2 : GHC.Types.Int | (x2 == (2 : int))}2 141: where GHC.Types.Intn = GHC.Types.Char -> GHC.Types.Intord {x2 : GHC.Types.Char | (x2 == c)}c 142: GHC.Types.Intm = {x2 : GHC.Types.Int | (x2 == n)}n x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x4 : GHC.Types.Int | (x4 == (x1 - x2))}- {x2 : GHC.Types.Int | (x2 == (65536 : int))}0x10000 143: GHC.Word.Word16lo = x1:GHC.Types.Int -> {x2 : GHC.Word.Word16 | (x2 == x1)}fromIntegral (GHC.Types.Int -> GHC.Word.Word16) -> GHC.Types.Int -> GHC.Word.Word16$ GHC.Types.Int({x2 : GHC.Types.Int | (x2 == m)}m GHC.Types.Int -> GHC.Types.Int -> GHC.Types.Int`shiftR` {x2 : GHC.Types.Int | (x2 == (10 : int))}10) x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x4 : GHC.Types.Int | (x4 == (x1 + x2))}+ {x2 : GHC.Types.Int | (x2 == (55296 : int))}0xD800 144: GHC.Word.Word16hi = x1:GHC.Types.Int -> {x2 : GHC.Word.Word16 | (x2 == x1)}fromIntegral (GHC.Types.Int -> GHC.Word.Word16) -> GHC.Types.Int -> GHC.Word.Word16$ GHC.Types.Int({x2 : GHC.Types.Int | (x2 == m)}m GHC.Types.Int -> GHC.Types.Int -> GHC.Types.Int.&. {x2 : GHC.Types.Int | (x2 == (1023 : int))}0x3FF) x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x4 : GHC.Types.Int | (x4 == (x1 + x2))}+ {x2 : GHC.Types.Int | (x2 == (56320 : int))}0xDC00 145: 146: 147: {-@ measure isUnknown :: Size -> Prop 148: isUnknown (Exact n) = false 149: isUnknown (Max n) = false 150: isUnknown (Unknown) = true 151: @-} 152: {-@ measure getSize :: Size -> Int 153: getSize (Exact n) = n 154: getSize (Max n) = n 155: @-} 156: 157: {-@ invariant {v:Size | (getSize v) >= 0} @-} 158: 159: data Size = Exact {-# UNPACK #-} !Int -- ^ Exact size. 160: | Max {-# UNPACK #-} !Int -- ^ Upper bound on size. 161: | Unknown -- ^ Unknown size. 162: deriving (Eq, Show) 163: 164: {-@ upperBound :: k:Nat -> s:Size -> {v:Nat | v = ((isUnknown s) ? k : (getSize s))} @-} 165: upperBound :: Int -> Size -> Int 166: x1:{v : GHC.Types.Int | (v >= 0)} -> x2:TextInternal.Size -> {v : GHC.Types.Int | (v == (if ((isUnknown x2)) then x1 else (getSize x2))) && (v >= 0)}upperBound _ (Exact n) = {x2 : GHC.Types.Int | (x2 == n)}n 167: upperBound _ (Max n) = {x2 : GHC.Types.Int | (x2 == n)}n 168: upperBound k _ = {x2 : GHC.Types.Int | (x2 >= 0)}k 169: 170: data Step s a = Done 171: | Skip !s 172: | Yield !a !s 173: 174: data Stream a = 175: forall s. Stream 176: (s -> Step s a) -- stepper function 177: !s -- current state 178: !Size -- size hint 179: 180: {-@ shiftL :: i:Nat -> n:Nat -> {v:Nat | ((n = 1) => (v = (i * 2)))} @-} 181: shiftL :: Int -> Int -> Int 182: x1:{v : GHC.Types.Int | (v >= 0)} -> x2:{v : GHC.Types.Int | (v >= 0)} -> {v : GHC.Types.Int | ((x2 == 1) => (v == (x1 * 2))) && (v >= 0)}shiftL = forall a. aundefined -- (I# x#) (I# i#) = I# (x# `iShiftL#` i#) 183: 184: {-@ pack :: String -> Text @-} 185: pack :: String -> Text 186: [GHC.Types.Char] -> TextInternal.Textpack = forall a. aundefined -- not "actually" using
The Text Lifecycle
text splits the reading and writing array operations between two
types of arrays, immutable Arrays and mutable MArrays. This leads to
the following general lifecycle:
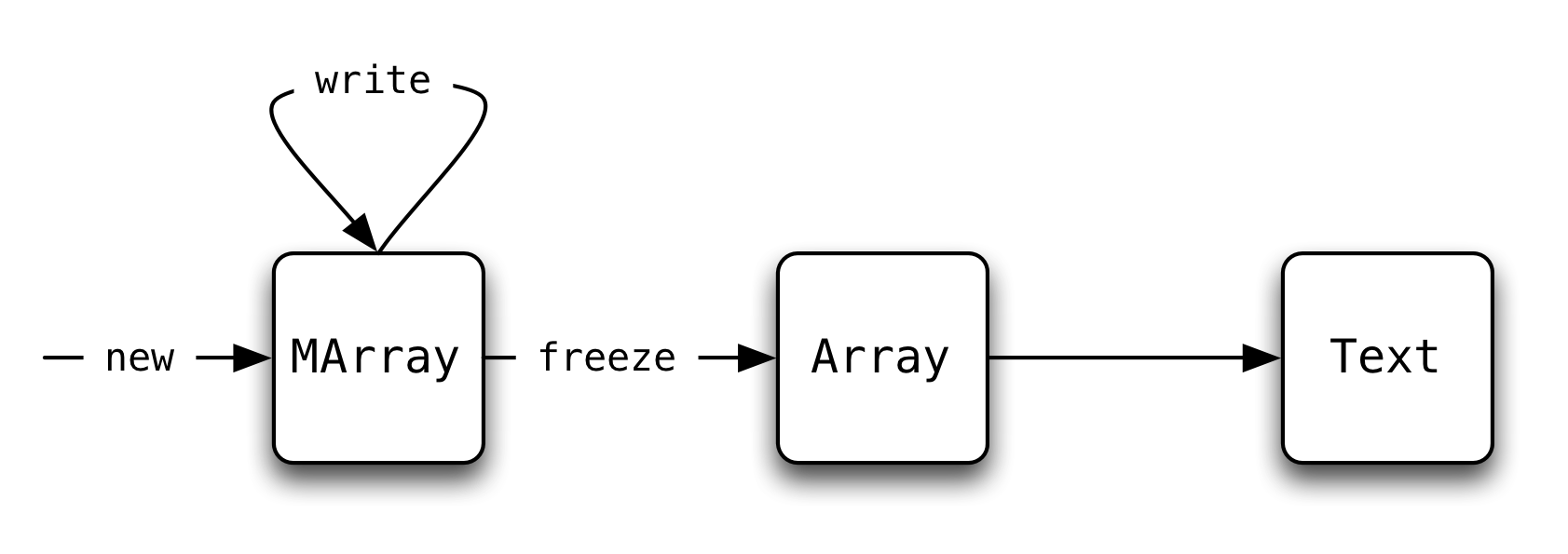
The main four array operations we care about are:
- creating an
MArray, - writing into an
MArray, - freezing an
MArrayinto anArray, and - reading from an
Array.
Creating an MArray
The (mutable) MArray is a thin wrapper around GHC’s primitive
MutableByteArray#, additionally carrying the number of Word16s it
can store.
221: data MArray s = MArray { forall a. (TextInternal.MArray a) -> (GHC.Prim.MutableByteArray# a)maBA :: MutableByteArray# s 222: , forall a. x1:(TextInternal.MArray a) -> {v : GHC.Types.Int | (v == (maLen x1)) && (v >= 0)}maLen :: !Int 223: } 224: {-@ data MArray s = MArray { maBA :: MutableByteArray# s 225: , maLen :: Nat 226: } 227: @-}
It doesn’t make any sense to have a negative length, so we add a
simple refined data definition which states that maLen must be
non-negative. A nice new side effect of adding this refined data
definition is that we also get the following accessor measures for free
234: {-@ measure maBA :: MArray s -> MutableByteArray# s 235: maBA (MArray a l) = a 236: @-} 237: {-@ measure maLen :: MArray s -> Int 238: maLen (MArray a l) = l 239: @-}
With our free accessor measures in hand, we can start building MArrays.
245: {-@ type MArrayN s N = {v:MArray s | (maLen v) = N} @-} 246: 247: {-@ new :: forall s. n:Nat -> ST s (MArrayN s n) @-} 248: forall a. x1:{v : GHC.Types.Int | (v >= 0)} -> (GHC.ST.ST a {v : (TextInternal.MArray a) | ((maLen v) == x1)})new {v : GHC.Types.Int | (v >= 0)}n 249: | {x3 : GHC.Types.Int | (x3 == n) && (x3 >= 0)}n x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 < x2))}< {x2 : GHC.Types.Int | (x2 == (0 : int))}0 x1:GHC.Types.Bool -> x2:GHC.Types.Bool -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (((Prop x1)) || ((Prop x2))))}|| {x3 : GHC.Types.Int | (x3 == n) && (x3 >= 0)}n GHC.Types.Int -> GHC.Types.Int -> GHC.Types.Int.&. {x2 : GHC.Types.Int | (x2 == highBit)}highBit x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 /= x2))}/= {x2 : GHC.Types.Int | (x2 == (0 : int))}0 = [GHC.Types.Char] -> {x1 : (GHC.ST.ST a {x2 : (TextInternal.MArray a) | false}) | false}error {x2 : [GHC.Types.Char] | ((len x2) >= 0)}"size overflow" 250: | otherwise = ((GHC.Prim.State# a) -> ((GHC.Prim.State# a), {x7 : (TextInternal.MArray a) | ((maLen x7) == n)})) -> (GHC.ST.ST a {x3 : (TextInternal.MArray a) | ((maLen x3) == n)})ST (((GHC.Prim.State# a) -> ((GHC.Prim.State# a), {x17 : (TextInternal.MArray a) | ((maLen x17) == n)})) -> (GHC.ST.ST a {x12 : (TextInternal.MArray a) | ((maLen x12) == n)})) -> ((GHC.Prim.State# a) -> ((GHC.Prim.State# a), {x17 : (TextInternal.MArray a) | ((maLen x17) == n)})) -> (GHC.ST.ST a {x12 : (TextInternal.MArray a) | ((maLen x12) == n)})$ \(GHC.Prim.State# a)s1# -> 251: case GHC.Prim.Int# -> (GHC.Prim.State# a) -> ((GHC.Prim.State# a), (GHC.Prim.MutableByteArray# a))newByteArray# {x2 : GHC.Prim.Int# | (x2 == len)}len# {x2 : (GHC.Prim.State# a) | (x2 == s1)}s1# of 252: (# s2#, marr# #) -> forall a b. a -> b -> (a, b)(# {x2 : (GHC.Prim.State# a) | (x2 == s2)}s2#, x1:(GHC.Prim.MutableByteArray# a) -> x2:{x5 : GHC.Types.Int | (x5 >= 0)} -> {x3 : (TextInternal.MArray a) | ((maBA x3) == x1) && ((maLen x3) == x2)}MArray {x2 : (GHC.Prim.MutableByteArray# a) | (x2 == marr)}marr# {x3 : GHC.Types.Int | (x3 == n) && (x3 >= 0)}n #) 253: where !(I# len#) = x1:{x12 : GHC.Types.Int | (x12 == n) && (x12 == (if ((isUnknown TextInternal.Unknown)) then n else (getSize TextInternal.Unknown))) && (x12 >= 0)} -> {x8 : GHC.Types.Int | ((x1 == 1) => (x8 == (x1 * 2))) && ((x1 == 1) => (x8 == (n * 2))) && ((n == 1) => (x8 == (x1 * 2))) && ((n == 1) => (x8 == (n * 2))) && (x8 >= 0) && (x8 >= x1) && (x8 >= n)}bytesInArray {x3 : GHC.Types.Int | (x3 == n) && (x3 >= 0)}n 254: GHC.Types.InthighBit = GHC.Types.IntmaxBound GHC.Types.Int -> GHC.Types.Int -> GHC.Types.Int`xor` (GHC.Types.IntmaxBound GHC.Types.Int -> GHC.Types.Int -> GHC.Types.Int`shiftR` {x2 : GHC.Types.Int | (x2 == (1 : int))}1) 255: n:{VV : GHC.Types.Int | (VV == n) && (VV == (if ((isUnknown TextInternal.Unknown)) then n else (getSize TextInternal.Unknown))) && (VV >= 0)} -> {VV : GHC.Types.Int | ((n == 1) => (VV == (n * 2))) && ((n == 1) => (VV == (n * 2))) && ((n == 1) => (VV == (n * 2))) && ((n == 1) => (VV == (n * 2))) && (VV >= 0) && (VV >= n) && (VV >= n)}bytesInArray {VV : GHC.Types.Int | (VV == n) && (VV == (if ((isUnknown TextInternal.Unknown)) then n else (getSize TextInternal.Unknown))) && (VV >= 0)}n = {x5 : GHC.Types.Int | (x5 == n) && (x5 == n) && (x5 == (if ((isUnknown TextInternal.Unknown)) then n else (getSize TextInternal.Unknown))) && (x5 >= 0)}n x1:{x7 : GHC.Types.Int | (x7 >= 0)} -> x2:{x5 : GHC.Types.Int | (x5 >= 0)} -> {x3 : GHC.Types.Int | ((x2 == 1) => (x3 == (x1 * 2))) && (x3 >= 0)}`shiftL` {x2 : GHC.Types.Int | (x2 == (1 : int))}1
new n is an ST action that produces an MArray s with n slots,
denoted by the type alias MArrayN s n. Note that we are not talking
about bytes here, text deals with Word16s internally and as such
we actualy allocate 2*n bytes. While this may seem like a lot of
code to just create an array, the verification process here is quite
simple. LiquidHaskell simply recognizes that the n used to construct
the returned array (MArray marr# n) is the same n passed to
new. It should be noted that we’re abstracting away some detail here
with respect to the underlying MutableByteArray#, specifically we’re
making the assumption that any unsafe operation will be caught and
dealt with before the MutableByteArray# is touched.
Writing into an MArray
Once we have an MArray, we’ll want to be able to write our
data into it. A Nat is a valid index into an MArray if it is
less than the number of slots, for which we have another type alias
MAValidI. text checks this property at run-time, but LiquidHaskell
can statically prove that the error branch is unreachable.
279: {-@ type MAValidI MA = {v:Nat | v < (maLen MA)} @-} 280: {-@ unsafeWrite :: ma:MArray s -> MAValidI ma -> Word16 -> ST s () @-} 281: forall a. x1:(TextInternal.MArray a) -> {v : GHC.Types.Int | (v >= 0) && (v < (maLen x1))} -> GHC.Word.Word16 -> (GHC.ST.ST a ())unsafeWrite MArray{..} {v : GHC.Types.Int | (v >= 0)}i@(I# i#) (W16# e#) 282: | {x5 : GHC.Types.Int | (x5 == i) && (x5 == i) && (x5 == (i : int)) && (x5 >= 0)}i x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 < x2))}< {x2 : GHC.Types.Int | (x2 == (0 : int))}0 x1:GHC.Types.Bool -> x2:GHC.Types.Bool -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (((Prop x1)) || ((Prop x2))))}|| {x5 : GHC.Types.Int | (x5 == i) && (x5 == i) && (x5 == (i : int)) && (x5 >= 0)}i x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 >= x2))}>= {x2 : GHC.Types.Int | (x2 >= 0)}maLen = {x3 : [GHC.Types.Char] | false} -> (GHC.ST.ST a ())liquidError {x2 : [GHC.Types.Char] | ((len x2) >= 0)}"out of bounds" 283: | otherwise = ((GHC.Prim.State# a) -> ((GHC.Prim.State# a), ())) -> (GHC.ST.ST a ())ST (((GHC.Prim.State# a) -> ((GHC.Prim.State# a), ())) -> (GHC.ST.ST a ())) -> ((GHC.Prim.State# a) -> ((GHC.Prim.State# a), ())) -> (GHC.ST.ST a ())$ \(GHC.Prim.State# a)s1# -> 284: case (GHC.Prim.MutableByteArray# a) -> GHC.Prim.Int# -> GHC.Prim.Word# -> (GHC.Prim.State# a) -> (GHC.Prim.State# a)writeWord16Array# (GHC.Prim.MutableByteArray# a)maBA {x2 : GHC.Prim.Int# | (x2 == i)}i# {x2 : GHC.Prim.Word# | (x2 == e)}e# {x2 : (GHC.Prim.State# a) | (x2 == s1)}s1# of 285: s2# -> forall a b. a -> b -> (a, b)(# (GHC.Prim.State# a)s2#, {x2 : () | (x2 == GHC.Tuple.())}() #)
So now we can write individual Word16s into an array, but maybe we
have a whole bunch of text we want to dump into the array. Remember,
text is supposed to be fast!
C has memcpy for cases like this but it’s notoriously unsafe; with
the right type however, we can regain safety. text provides a wrapper around
memcpy to copy n elements from one MArray to another.
296: {-@ type MAValidO MA = {v:Nat | v <= (maLen MA)} @-} 297: {-@ copyM :: dest:MArray s 298: -> didx:MAValidO dest 299: -> src:MArray s 300: -> sidx:MAValidO src 301: -> {v:Nat | (((didx + v) <= (maLen dest)) && ((sidx + v) <= (maLen src)))} 303: -> ST s () 304: @-} 305: forall a. x1:(TextInternal.MArray a) -> x2:{v : GHC.Types.Int | (v >= 0) && (v <= (maLen x1))} -> x3:(TextInternal.MArray a) -> x4:{v : GHC.Types.Int | (v >= 0) && (v <= (maLen x3))} -> {v : GHC.Types.Int | (v >= 0) && ((x2 + v) <= (maLen x1)) && ((x4 + v) <= (maLen x3))} -> (GHC.ST.ST a ())copyM (TextInternal.MArray a)dest {v : GHC.Types.Int | (v >= 0) && (v <= (maLen dest))}didx (TextInternal.MArray a)src {v : GHC.Types.Int | (v >= 0) && (v <= (maLen src))}sidx {v : GHC.Types.Int | (v >= 0) && ((didx + v) <= (maLen dest)) && ((sidx + v) <= (maLen src))}count 306: | {x5 : GHC.Types.Int | (x5 == count) && (x5 >= 0) && ((didx + x5) <= (maLen dest)) && ((sidx + x5) <= (maLen src))}count x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 <= x2))}<= {x2 : GHC.Types.Int | (x2 == (0 : int))}0 = () -> (GHC.ST.ST a ())return {x2 : () | (x2 == GHC.Tuple.())}() 307: | otherwise = 308: {x6 : GHC.Types.Bool | ((Prop x6))} -> (GHC.ST.ST a ()) -> (GHC.ST.ST a ())liquidAssert ({x4 : GHC.Types.Int | (x4 == sidx) && (x4 >= 0) && (x4 <= (maLen src))}sidx x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x4 : GHC.Types.Int | (x4 == (x1 + x2))}+ {x5 : GHC.Types.Int | (x5 == count) && (x5 >= 0) && ((didx + x5) <= (maLen dest)) && ((sidx + x5) <= (maLen src))}count x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 <= x2))}<= x1:(TextInternal.MArray a) -> {x3 : GHC.Types.Int | (x3 == (maLen x1)) && (x3 >= 0)}maLen {x2 : (TextInternal.MArray a) | (x2 == src)}src) ((GHC.ST.ST a ()) -> (GHC.ST.ST a ())) -> ((GHC.Types.IO ()) -> (GHC.ST.ST a ())) -> (GHC.Types.IO ()) -> exists [(GHC.ST.ST a ())].(GHC.ST.ST a ()). 309: {x6 : GHC.Types.Bool | ((Prop x6))} -> (GHC.ST.ST a ()) -> (GHC.ST.ST a ())liquidAssert ({x4 : GHC.Types.Int | (x4 == didx) && (x4 >= 0) && (x4 <= (maLen dest))}didx x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x4 : GHC.Types.Int | (x4 == (x1 + x2))}+ {x5 : GHC.Types.Int | (x5 == count) && (x5 >= 0) && ((didx + x5) <= (maLen dest)) && ((sidx + x5) <= (maLen src))}count x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 <= x2))}<= x1:(TextInternal.MArray a) -> {x3 : GHC.Types.Int | (x3 == (maLen x1)) && (x3 >= 0)}maLen {x2 : (TextInternal.MArray a) | (x2 == dest)}dest) ((GHC.ST.ST a ()) -> (GHC.ST.ST a ())) -> ((GHC.Types.IO ()) -> (GHC.ST.ST a ())) -> (GHC.Types.IO ()) -> exists [(GHC.ST.ST a ())].(GHC.ST.ST a ()). 310: (GHC.Types.IO ()) -> (GHC.ST.ST a ())unsafeIOToST ((GHC.Types.IO ()) -> (GHC.ST.ST a ())) -> (GHC.Types.IO ()) -> (GHC.ST.ST a ())$ (GHC.Prim.MutableByteArray# a) -> Foreign.C.Types.CSize -> (GHC.Prim.MutableByteArray# a) -> Foreign.C.Types.CSize -> Foreign.C.Types.CSize -> (GHC.Types.IO ())memcpyM ((TextInternal.MArray a) -> (GHC.Prim.MutableByteArray# a)maBA {x2 : (TextInternal.MArray a) | (x2 == dest)}dest) (x1:GHC.Types.Int -> {x2 : Foreign.C.Types.CSize | (x2 == x1)}fromIntegral {x4 : GHC.Types.Int | (x4 == didx) && (x4 >= 0) && (x4 <= (maLen dest))}didx) 311: ((TextInternal.MArray a) -> (GHC.Prim.MutableByteArray# a)maBA {x2 : (TextInternal.MArray a) | (x2 == src)}src) (x1:GHC.Types.Int -> {x2 : Foreign.C.Types.CSize | (x2 == x1)}fromIntegral {x4 : GHC.Types.Int | (x4 == sidx) && (x4 >= 0) && (x4 <= (maLen src))}sidx) 312: (x1:GHC.Types.Int -> {x2 : Foreign.C.Types.CSize | (x2 == x1)}fromIntegral {x5 : GHC.Types.Int | (x5 == count) && (x5 >= 0) && ((didx + x5) <= (maLen dest)) && ((sidx + x5) <= (maLen src))}count)
copyM requires two MArrays and valid offsets into each – note
that a valid offset is not necessarily a valid index, it may
be one element out-of-bounds – and a count of elements to copy.
The count must represent a valid region in each MArray, in
other words offset + count <= length must hold for each array.
You might notice the two liquidAsserts in the function, these were converted
from Control.Exception.assert so that LiquidHaskell will statically guarantee
they will never fail. The trick is simply to give
liquidAssert the type
325: {-@ liquidAssert :: {v:Bool | (Prop v)} -> a -> a @-}
Freezing an MArray into an Array
Before we can package up our MArray into a Text, we need to
freeze it, preventing any further mutation. The key property here is
of course that the frozen Array should have the same length as the
MArray.
Just as MArray wraps a mutable array, Array wraps an immutable
ByteArray# and carries its length in Word16s.
339: data Array = Array 340: { TextInternal.Array -> GHC.Prim.ByteArray#aBA :: ByteArray# 341: , x1:TextInternal.Array -> {v : GHC.Types.Int | (v == (aLen x1)) && (v >= 0)}aLen :: !Int 342: }
As before, we get free accessor measures aBA and aLen so we can
refer to the components of an Array in our refinements. Using these
measures, we can define
350: {-@ type ArrayN N = {v:Array | (aLen v) = N} @-} 351: {-@ unsafeFreeze :: ma:MArray s -> ST s (ArrayN (maLen ma)) @-} 352: forall a. x1:(TextInternal.MArray a) -> (GHC.ST.ST a {v : TextInternal.Array | ((aLen v) == (maLen x1))})unsafeFreeze MArray{..} = ((GHC.Prim.State# a) -> ((GHC.Prim.State# a), {x5 : TextInternal.Array | false})) -> (GHC.ST.ST a {x2 : TextInternal.Array | false})ST (((GHC.Prim.State# a) -> {x11 : ((GHC.Prim.State# a), {x13 : TextInternal.Array | false}) | false}) -> (GHC.ST.ST a {x9 : TextInternal.Array | false})) -> ((GHC.Prim.State# a) -> {x11 : ((GHC.Prim.State# a), {x13 : TextInternal.Array | false}) | false}) -> (GHC.ST.ST a {x9 : TextInternal.Array | false})$ \(GHC.Prim.State# a)s# -> 353: forall a b. a -> b -> (a, b)(# {x2 : (GHC.Prim.State# a) | (x2 == s)}s#, x1:GHC.Prim.ByteArray# -> x2:{x5 : GHC.Types.Int | (x5 >= 0)} -> {x3 : TextInternal.Array | ((aBA x3) == x1) && ((aLen x3) == x2)}Array ((GHC.Prim.MutableByteArray# a) -> {x1 : GHC.Prim.ByteArray# | false}unsafeCoerce# (GHC.Prim.MutableByteArray# a)maBA) {x2 : GHC.Types.Int | (x2 >= 0)}maLen #)
Again, LiquidHaskell is happy to prove our specification as we simply
copy the length parameter maLen over into the Array.
Reading from an Array
Finally, we will eventually want to read a value out of the
Array. As with unsafeWrite we require a valid index into the
Array, which we denote using the AValidI alias.
366: {-@ type AValidI A = {v:Nat | v < (aLen A)} @-} 367: {-@ unsafeIndex :: a:Array -> AValidI a -> Word16 @-} 368: x1:TextInternal.Array -> {v : GHC.Types.Int | (v >= 0) && (v < (aLen x1))} -> GHC.Word.Word16unsafeIndex Array{..} {v : GHC.Types.Int | (v >= 0)}i@(I# i#) 369: | {x5 : GHC.Types.Int | (x5 == i) && (x5 == i) && (x5 == (i : int)) && (x5 >= 0)}i x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 < x2))}< {x2 : GHC.Types.Int | (x2 == (0 : int))}0 x1:GHC.Types.Bool -> x2:GHC.Types.Bool -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (((Prop x1)) || ((Prop x2))))}|| {x5 : GHC.Types.Int | (x5 == i) && (x5 == i) && (x5 == (i : int)) && (x5 >= 0)}i x1:GHC.Types.Int -> x2:GHC.Types.Int -> {x2 : GHC.Types.Bool | (((Prop x2)) <=> (x1 >= x2))}>= {x2 : GHC.Types.Int | (x2 >= 0)}aLen = {x2 : [GHC.Types.Char] | false} -> GHC.Word.Word16liquidError {x2 : [GHC.Types.Char] | ((len x2) >= 0)}"out of bounds" 370: | otherwise = case GHC.Prim.ByteArray# -> GHC.Prim.Int# -> GHC.Prim.Word#indexWord16Array# GHC.Prim.ByteArray#aBA {x2 : GHC.Prim.Int# | (x2 == i)}i# of 371: r# -> (GHC.Prim.Word# -> GHC.Word.Word16W16# GHC.Prim.Word#r#)
As before, LiquidHaskell can easily prove that the error branch is unreachable!
Before moving on, let’s take a quick step back and recall the example that motivated this whole discussion.
381: TextInternal.Text -> GHC.Types.Int -> GHC.Types.CharcharAt (Text a o l) GHC.Types.Inti = GHC.Word.Word16 -> exists [GHC.Types.Int].GHC.Types.Charword2char (GHC.Word.Word16 -> GHC.Types.Char) -> GHC.Word.Word16 -> GHC.Types.Char$ x1:TextInternal.Array -> {x4 : GHC.Types.Int | (x4 >= 0) && (x4 < (aLen x1))} -> GHC.Word.Word16unsafeIndex {x2 : TextInternal.Array | (x2 == a)}a {x2 : GHC.Types.Int | (x2 == i)}i 382: where GHC.Word.Word16 -> exists [GHC.Types.Int].GHC.Types.Charword2char = GHC.Types.Int -> GHC.Types.Charchr (GHC.Types.Int -> GHC.Types.Char) -> (GHC.Word.Word16 -> GHC.Types.Int) -> GHC.Word.Word16 -> exists [GHC.Types.Int].GHC.Types.Char. x1:GHC.Word.Word16 -> {x2 : GHC.Types.Int | (x2 == x1)}fromIntegral
Fantastic! LiquidHaskell is telling us that our call to
unsafeIndex is, in fact, unsafe because we don’t know
that i is a valid index.
Wrapping it all up
Now we can finally define the core datatype of the text package!
A Text value consists of an array, an offset, and a length.
395: data Text = Text Array Int Int
The offset and length are Nats satisfying two properties:
off <= aLen arr, andoff + len <= aLen arr
404: {-@ type TValidO A = {v:Nat | v <= (aLen A)} @-} 405: {-@ type TValidL O A = {v:Nat | (v+O) <= (aLen A)} @-} 406: 407: {-@ data Text [tlen] = Text (tarr :: Array) 408: (toff :: TValidO tarr) 409: (tlen :: TValidL toff tarr) 410: @-}
These invariants ensure that any index we pick between off and
off + len will be a valid index into arr. If you’re not quite
convinced, consider the following Texts.
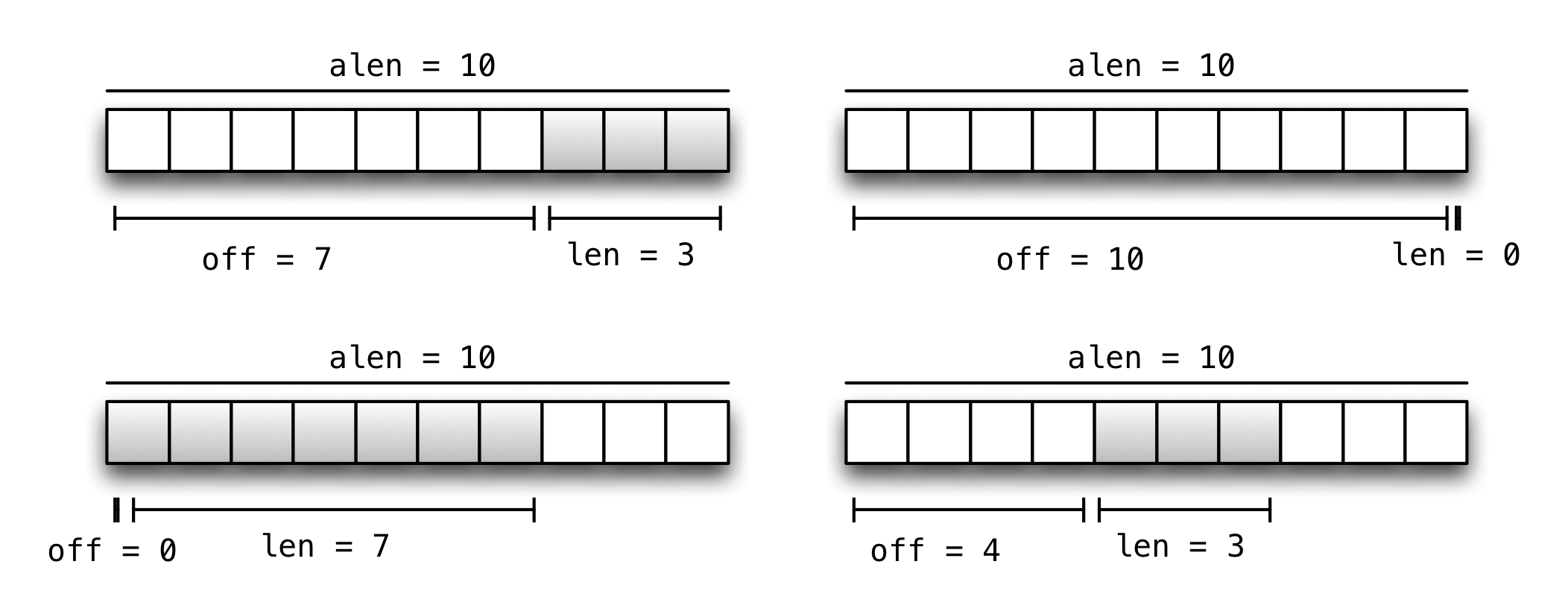
Multiple valid Text configurations, all using an Array with 10 slots. The valid slots are shaded. Note that the key invariant is that off + len <= aLen.
Phew, that was a lot for one day, next time we’ll take a look at how to handle
uncode in text.
-
This function is bad for numerous reasons, least of which is that
Data.Text.indexis already provided.↩